Introduction to Mangrove
What is the problem Mangrove is trying to solve?
A key feature of ExP Platform is the ability for the customers to easily define metrics to analyze experiment data, schedule automated jobs to compute these metrics for an experiment, and then display the results of the analysis on a scorecard. These metrics are defined using an internal domain-specific language (DSL): either directly by writing code, or one can use a UI layer built on top of it. Metrics are organized into metric sets containing all the available metrics, scorecard layouts, etc. See metrics docs for more details.
Having a DSL has many benefits:
- metrics are easy to define and the definitions are concise (see examples below),
- ExP can automate metric variance estimations since we can control what types of metrics are allowed,
- ExP can automate slicing data by segments,
- ExP can do deep validations helping customers with their analyses.
However, customers' data can live in different storage systems that can be accessed by different compute fabrics, e.g. in Cosmos using Scope, or in Azure Blob Storage using Databricks to run Spark jobs. Thus, for ExP to be able to submit an analysis with metrics defined in the DSL, there needs to be a translation DSL → script in a given fabric, e.g. DSL → Scope script for a customer using Cosmos.
Mangrove is the "vNext" library responsible for generating fabric-specific scripts from the DSL. There are other systems doing this, e.g. Foray for Scope and MetricNet for Spark. Mangrove is the first such system that can generate scripts for multiple fabrics at once, and is planned to replace the other solutions.
Brief description of the metrics DSL
Before we proceed, let us give a simple example of a metric defined using the DSL.
Suppose we have a data source with just three columns: Event containing unique event IDs,
which is also the primary key; User containing user IDs, where each user can have many events;
and Revenue containing the revenues generated by the events. Most events probably
generate 0 revenue, but perhaps purchase events generate some non-zero value. Then,
a metric computing average revenue per user could be defined as follows:
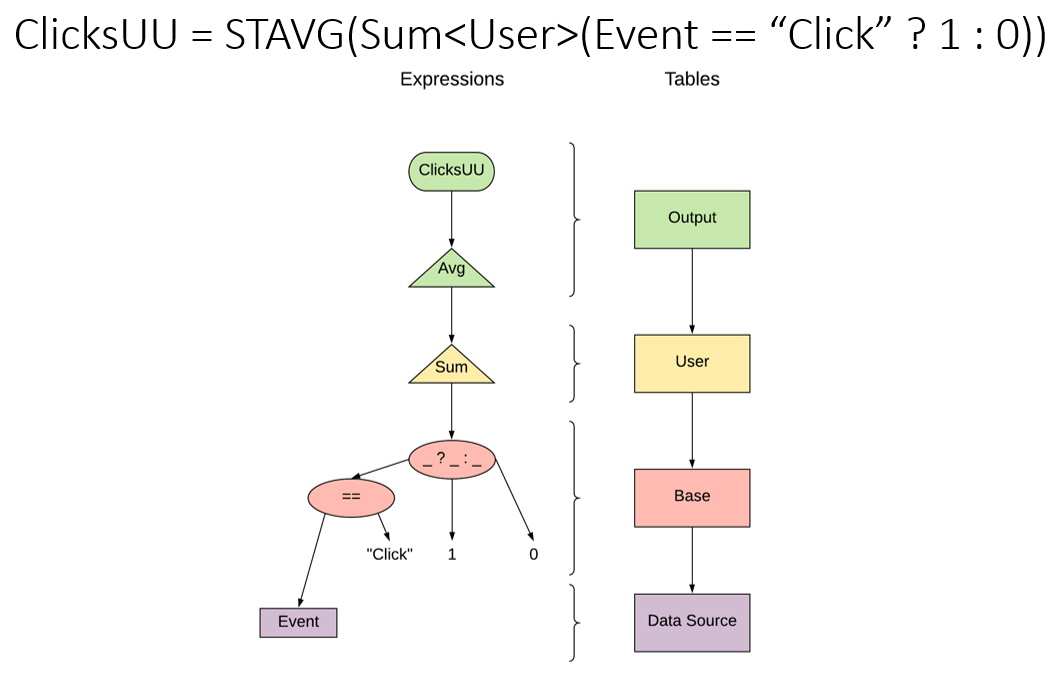
RevenuePerUser = STAVG(SUM<User>(Revenue))
The expression is computed "inside-out":
- First,
SUM<User>(Revenue)is computed. For each distinct user ID fromUsercolumn, all the values fromRevenuewill be summed up across all events. This gives us aUser-level table, where each user has the corresponding total revenue. - Next,
STAVGis applied that simply averages those values across all users. TheSTpart indicates that we need to compute statistics for it.
The language supports most basic operations (arithmetic, logical operations, string
operations, regex matching) and aggregations (MIN, MAX, SUM, AVG, PERCENTILE)
and
How does Mangrove fit into the scorecard pipeline?
Before diving into the details of how Mangrove works, let us have a quick overview of the scorecard pipeline. At a very high level, Mangrove's integration into the pipeline is the same as for other script gen frameworks we have.
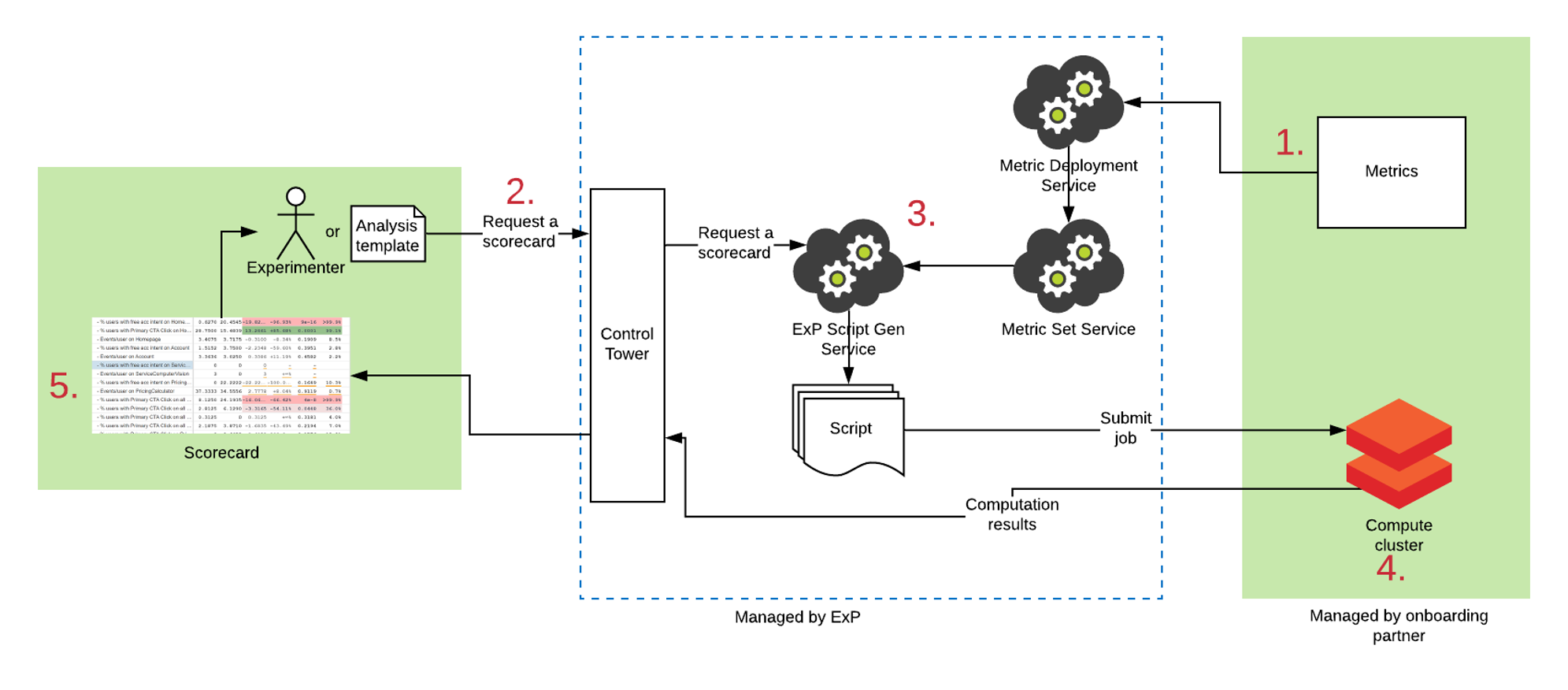
- Customers define their metrics using the DSL. Metric Deployment Service "builds" the metric set by parsing it into an intermediate object (more details below), validates it and uploads the artifact to the Metric Set Service.
- When a customer submits a request to generate a scorecard, the request gets to a script generation service. The request can be manual or auto-scheduled. Each request generates a config with the "run-time" information describing the job, see more details below.
- Script gen fetches the latest metric set artifact from a metric set service. Script gen uses the information from the request + the artifact to generate the right script for the job.
- The pipeline submits the generated script to the fabric and monitors it.
- Once the job succeeds, the results of the computation are uploaded to Anarepo DB, and the customer gets a link to the requested scorecard.
Key takeaway for Mangrove: script gen uses two objects to produce a script:
- Config: the "run-time" info describing the job.
- Metric set artifact: the "static" info describing the metrics.
What are the two inputs to Mangrove?
Config
A simple yaml file describing the job. The file gets parsed into an object described by ExtendedConfig. Here is a typical example:
# Which metric set to use.
MetricsPlanInfo:
Name: OutlookMobile
Version: latest
# Only include data from this time interval.
StartDateTime: 4/3/2019 2:00:00 AM
EndDateTime: 4/4/2019 12:00:00 AM
# Map flight name -> specification list, namely
# [numberline, flight name, allocation ID]. Some of them can be empty.
Flights:
Oulie3121cf: ['', Oulie3121cf, 30009499]
Oulie3121: ['', Oulie3121, 30009498]
# How to segment the data
SegmentGroups:
- Segments:
- FLIGHT
- Level: 1
AggregateAll: true
Segments:
- Market
- DeviceManufacturer
# Output path of the result of the computation described by the generated
# script. Not to be confused to the path of the generated script itself.
OutputPath: /local/projects/users/lsrep/Foray/2019/04/03/result.txt
# If this is not specified, Blitz will attempt to compute ALL metrics.
Profiles:
- OutlookMobile.OutlookAndroidShort.AB.Standard
# This tells Blitz to compute variance for all metrics.
RandomizationUnit: true
# We currently support Scope, Kusto, Hypercube, and SparkSql.
Extern: Scope
# Transform data from (short, wide) to (long, narrow) to prepare for loading
# into xCard. This is only supported for Scope.
Unpivot: true
Metric set artifact
In Mangrove, metric sets get converted into an object called
MetricsPlan. Each MetricsPlan
is a DAG (a syntax tree) of Tables
and Expressions describing the metrics,
plus some metadata like used DLLs, version, etc.
public class MetricsPlan
{
public IReadOnlyList<Table> Tables { get; }
public IReadOnlyList<Expression> Expressions { get; }
public MetricSetMetadata Metadata { get; }
}
public abstract class Table
{
public string Name { get; }
public abstract IReadOnlyList<Table> Parents { get; }
}
public abstract class Expression
{
public Table Table { get; }
public abstract IReadOnlyList<Expression> Parents { get; }
}
Each Expression belongs to some Table, and can have other Expressions as
parents. Tables can have other Tables as parents, but they don't know
which Expressions belong to it. This indeed makes MetricsPlan a DAG.
There are many kinds of expressions:
- Aggregations: unary (Max, Sum, Avg) and binary (Wavg, Percentile)
- Arithmetic operations (+, ==, &&, RegexMatch)
- Special: filters, “group by”s, custom functions,
There are many kinds of tables:
DataSource(e.g. read data from a view)AggregationUnionJoin
Expressions
Let's consider some simple examples of expressions.
x+ywould be translated to aBinaryOperationexpression of kindBinaryOperationKind.Plus, andxandyare its two parents, also some expressions.SUM<User>(Revenue)from the example above will be translated to aUnaryAggregationof typeUnaryAggregationKind.SUM, with its parentRevenuebeing aDataSourceColumnexpression.
Tables
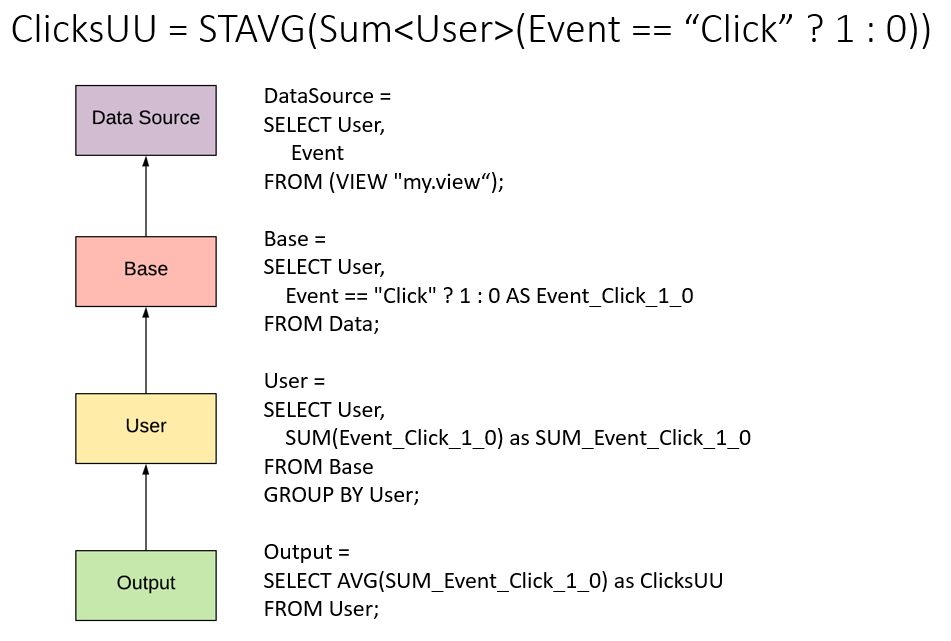
One can think of tables as SELECT statements. In the example
SUM<User>(Revenue) above, Revenue is selected from the data source table,
while SUM belongs to the table User since it creates a one-per-user value.
This is exactly what happens in the generated code!
Let's consider one more example of a metric, the corresponding expressions and tables, and the kind of SQL code that it could be translated to. As this example shows, thinking about tables as SELECT statements is indeed justified.
Operating on Expressions and Tables
Expression objects follow the visitor pattern to make operations on them type safe. So, the fundamental operation on expressions is to implement the IExpressionVisitor interface, i.e. for each expression subclass, a "visit" method which accepts a parameter of that type. Since there are many expression types, visitors are naturally quite verbose. Moreover, since expressions are immutable, any operation which would change an expression must replace it and, by implication, all expressions depending on that expression. This would lead to a proliferation of boilerplate code for:
- Visiting each expression type.
- Propagating expression replacement.
While developers can implement IExpressionVisitor, directly, it is easier and less error-prone to use the following base classes, each of which implement that interface.
ChangeExpressions, which gives you the option of either saying "replace this specific expression type in a specified way", or "swap out the parent of an expression in a specified way", and handles the boilerplate of visiting all expression types and propagating replacements.
There is already a robust set of expression visitors subclassing this base class, which means that many new operations on expressions can be implemented by composing existing functionality.
The same is true for Table, with ITableVisitor and ChangeTables.
How does Mangrove work?
What is the general flow?
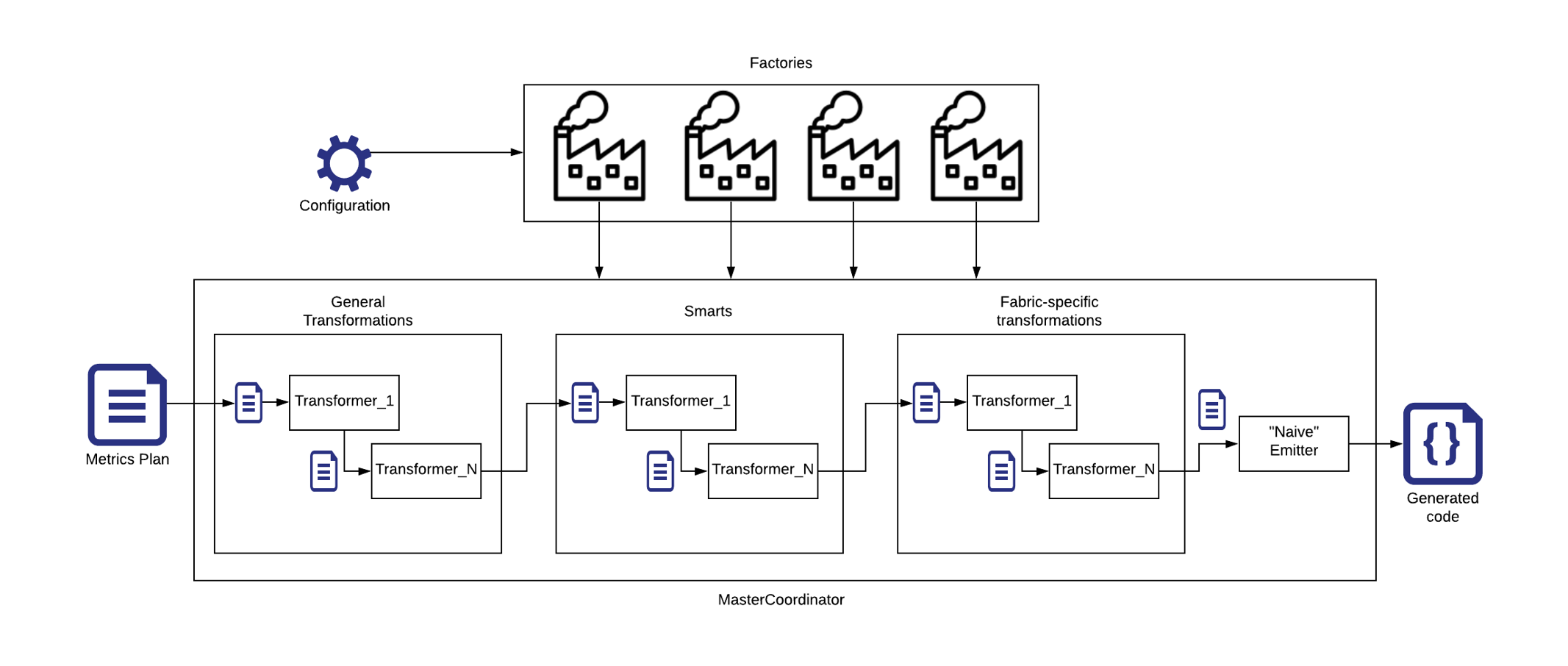
Blitz is the executable wrapping Mangrove libraries. It is used to run Mangrove. Emit command is the entry point. The logical flow is as follows:
- Deserialize the config.
- Based on
ExtendedConfig.MetricsPlanInfo, fetch the rightMetricsPlanobject from the Metric Service. - Apply Blitz extensions. These are transformations that allow modifying both the config and the plan before the main flow.
- MasterCoordinator uses
factories
to create a series of transformers
based on the information in the
config. Transformers modify theMetricsPlan:
- Remove unnecessary nodes and only keep what is needed for this particular analysis.
- Add expressions to compute metric variance.
- Add logic for doing segmentation.
- Optimize by deduplicating expressions, etc. Factories are used to make transformers fabric-agnostic.
- After the transformers, an emitter is applied to generate the script.
How to try it out locally?
There are two main ways to run Mangrove locally.
Blitz binary
Use Blitz executable to run Mangrove and generate a script locally. Please follow instructions in this article.
Integration tests
Clone the repo and run Mangrove E2E tests in VS. For the initial setup, follow instructions here. Then run these E2E tests.
These tests:
- Generate the scripts targeting different fabrics.
- Run the generated scripts using synthetic data.
- Make sure the results (metric values, variances) exactly match the expected ground truth.
The tests use different metric sets:
- MangroveBugBash is a "production" metric set. It's registed in Vivace, is compiled by MDL Core and deployed to the Metric Service. This is our main metric set.
- ComplexData
is a yaml metric set that is compiled by an internal
Mangrove compiler.
It is almost a replica of
MangroveBugBashbut the latter has more metrics and features tested due to the limitations of the Mangrove compiler. - SimpleData is a tiny metric set to help with really hands-on E2E debugging.
The E2E tests are using different configs for different scenarios. We have E2E tests for:
- AB scorecards: regular, triggered, filtered.
- Retrospective AA.
- Seedfinder.
- AA stream generation.
Moreover, we have tests using production metric sets to generate code. These are not really E2E since we don't run the jobs, but we still ensure the scripts generate succesfully.
Remarks on the code base structure
Code base is split into two parts: "closed source" and "open source". The idea is that any ExP-specific code should go into "closed source", and "open source" part should be clean enough to open source it in the future.
How can one contribute to the project?
For the detailed instructions on the requirements, setup, building and testing please see the README file.
How does deployment work for Mangrove?
We use Azure Pipelines to deploy Mangrove, see azure-pipelines.yml for the details.
Useful links and further reading
General
- ExP customer-facing documentation.
- Learn about visitor pattern.
- Compute are 2021 drill-in doc.
Mangrove-specific
- Mangrove README for setting things up.
- Mangrove repo.
- Mangrove docs.
- MangroveBugBash metric set used for E2E testing.
- Hypercube engine.
- Mangrove + Compiler 2021 drill-in doc.
- Mangrove paper for KDD.
Published packages
All the NuGet packages published by Mangrove have a name of the form
Mangrove.*. Here is a quick list:
Mangrove.Blitz: command line wrapper for Mangrove.Coordinator. See Blitz for instructions on how to install and use Blitz.Mangrove.ClosedSource.ScopeUserDefinedObjects: user-defined objects (UDOs) needed for operations in Scope.Mangrove.Coordinator: code for generating scripts from serialized MetricsPlan objects.Mangrove.Coordinator.Configuration: code for merging and (de)serializing configuration objects.Mangrove.Coordinator.Configuration.Contract: type system for (de)serializable computation configuration objects ("foray.ini v2").Mangrove.MetricSetEmitters: convert "fully transformed" metrics plans into runnable scripts.Mangrove.MetricSetSyntaxTree: type system for the syntax tree.Mangrove.MetricSetTransformers: operations on expressions, metric tables, etc.Mangrove.Logging: logging abstractions.Mangrove.Scratchpad: collection of helper and extension methods for querying metrics plans locally and on Corpnet.
They are all in the authenticated NuGet feed:
<add key="experimentation.Public" value="https://pkgs.dev.azure.com/experimentation/_packaging/Public/nuget/v3/index.json" />
If you are using Linqpad, you will need a personal access token to get access to
that feed. You can either get an existing token values from akv-experimentation-maven
key in Azure Key Vault mangrove-kv,
or you can generate a new personal access token by following the instructions here.