Retrospective AA and Seedfinder in Mangrove
| Owners | Approvers | Participants |
|---|---|---|
| Sasha Patotski, Ulf Knoblich | Venky Venkateshaiah, Daniel Miller | Xin Sun, Jun Qi, Craig Boucher, Kathy Guo |
Besides the usual A/B analysis, the two key analysis types are Retrospective AA (Retro AA) and Seedfinder. The first one is used to detect biases in the population split (as well as producing the so-called FlashResaltAAStream which is necessary for variance-reduced (VR) metrics for the Scope pipeline only), while the other is designed to pick a good split of users into treatment and control. This RFC (Request For Comment) describes the work that needs to be done to enable Mangrove to generate the scripts for these two types of analyses.
Introduction: What do Retro-AA and SeedFinder do?
Retro-AA and SeedFinder are often mentioned together because they are highly related.
For both, the data that is used is typically 7 days from before the experiment started.
Users (technically experiment units) are assigned flights based on which flight they would have been in,
had the experiment been active at that time. This assignment is done by the function
GetFlightFromFilter.
It takes the experiment configuration parameters listed above in addition to the
userid and FilterMap from the data, which contains the values for all traffic filters.
The filter values are matched against the FlightBucketMapping to retrieve the applicable buckets for all potential flights,
and the userid's hash is then compared against the buckets to determine which flight the user is in.
For Retro AA, once these flight allocations have been determined, a regular scorecard is computed with these "would be" flight assignments, and a certain subset of the computed metrics is checked for any statistically significant movements. This checking is called Retro AA test.
Moreover, during the Retro AA stage, an extra stream called FlashResaltAAStream is being produced and stored. Namely,
it is the metrics aggregated up to the experiment unit level, using the flight
assignment determined by the Retro AA. This stream is used for variance reduced metrics.
For Seedfinder, 200 different seeds are used to assign users to 200 different "would be" flights. Then a specified subset of the metrics is computed for each of the 200 hypothetical flight assignments, and the seed that gives the "closest" to an AA result is being selected as the seed for the actual experiment flight allocation.
For more information about these analyses, please see the wiki page about Seedfinder and the wiki page about Retrospective AA.
Requirements
As the result of this work, both analyses should no longer depend on Foray. In particular, Mangrove should receive all the necessary information in the config to be able to generate the scripts for the two new types of jobs, namely Retro AA and Seedfinder, for Scope and MV only.
Note: Hypercube has a separate pipeline to compute retro AA and seedfinder,
and merging it into the regular Mangrove workflow is out of scope for this RFC.
However, Hypercube retro AA pipeline is still using Foray modules to generate FlashResaltAAStream,
and it is part of this effort to replace these Foray modules in the Hypercube pipeline as well.
The main challenge
Mangrove already has most of the required logic for generating Seedfinder and Retro AA jobs. One of the main challenges is to make the changes to all the required components of the pipeline. Namely, this work would require the following:
- implementing additional transformers in Mangrove
- changes in the Config Gen service and Mangrove's
ComputationConfigobject to pass additional information to Mangrove, - creating new Blitz extensions,
- changing the AEther graphs that do the Retro AA analysis (both regular and Hypercube),
- changing MV logic for FLIGHT column handling and forcing MV aggregations to go from aggregation level to aggregation level, as opposed to doing everything in a single processor.
The required changes are described below.
Proposal
We propose the following changes.
Changes to Config Generation service and Mangrove Conputation Config object
Seedfinder and Retro AA analyses both require some additional information which we summarize below. For more details, see this wiki page.
- Filter to Flight Bucket Mapping: reflects the experiment traffic filter configuration, mapping a combination of filter values to a bucket allocation. For example consider
fltcf:MKT:en-us&ms:0=33,49|flttf:mkt:en-gb&ms:0=50,59
The general format is <flight1>:<fdfilters>=<buckets>|<flight1>:<market2>=<buckets>|<flight2>:<market3>=<bucket>|…,
where <fdfilters>=<fdfilter1>&<fdfilter2>&… with <fdfilter>=<filter_name:value>, and
<buckets>=starting_bucket_number,ending_bucket_number with the buckets ranging bewtween 1 and 1000.
- Hashing algorithm: hashing algorithm to be used, currently always "Spooky"
- Numberline Salt: salt to be used for hashing (in case of SeedFinder this is used as a prefix)
- Output path for experiment unit level table (i.e. path for
FlashResaltAAStreammentioned above) - List of metrics to use in SeedFinder
- Lower Seed Bound -- Lowest seed value for Seedfinder (appended to the numberline salt)
- Upper Seed Bound -- Highest seed value for Seedfinder (appended to the numberline salt)
See also the description in Mangrove To provide this information to Mangrove, we propose removing any Retro AA- and Seedfinder-related information from Mangrove completely, keeping only the output path for experiment unit level table as it is a useful feature to have for debugging purposes in general.
This would remove code generation framework's dependency on the specifics of the implementaion of the analysis.
We can achieve this by utilizing Blitz extensions,
plus creating an abstraction for the ComputationConfig. For the details on what these extensions would do,
see the section below. Let's call the abstraction for config simply IConfig for now.
At a high level, the Blitz extensions would receive an extended version of IConfig containing all the
additional information related to retro AA and Seedfinder. This extended version would need to be generated by
the Config Gen service. The Blitz extension will then modify the provided
plan using the extended config, and give Blitz the modified plan together with the IConfig stripped
of all the additional information (or Mangrove would simply expect IConfig and won't rely on any additonal information).
Blitz extensions
These are described in this document.
Retrospective AA
For retro AA, Flight column needs to be replaced with an Extern that is a call to the
GetFlightFromFilter method with the input parameters filled in using the
provided information (numberline salt, etc.). These is a simple wildcard replacement opetation.
The exact signature for this method is
Microsoft.Bing.Experimentation.UserHashingLib.UserHashing.GetFlightFromFilter(
UserIDColumn,
__numberline__,
"#NumberlineSalt#",
"#ResaltGroupName#",
"#FlightBucketMapping#",
EdgeFilterMapColumn ,
"#HashAlgorithm#").ToUpper()
The only information that would need to be passed on to Mangrove is the output path for experiment unit table, which we belive is a reasonable config parameter to have independently.
Seedfinder
For Seedfinder, the Blitz extension will add an ExternTable that would call the
SeedfinderSegmentProcessor.
This processor is used to generate the Seed column and add this new column as the only segment (except FLIGHT) in the config that would be
passed on to Mangrove.
Because MV and native Scope in Mangrove have different models for segmentation,
we will need to implement another version of the SeedfinderSegmentProcessor which would work with
the native Scope. We need to emphasize that this Scope processor does not do the actual segmentation.
It only creates the Seed column, and the segmentation logic is the same as usual.
Changes to AEther
There are two different Retro AA graphs: one uses Hypercube for the scorecard computation
and the other one uses xForay. Both graphs would need to be changed.
One common change to both graphs is that we will remove
the call to MSSv2 from the ForayApp.RetroAA.GenerateConfigAndParams module,
as we are going to use Blitz to make that call, see the details below.
Moreover, in addition to the other input parameters, ForayApp.RetroAA.GenerateConfigAndParams
needs to receive the analysis request. The reason for this is that
Config Gen does not have an open API to get the config files into AEther.
Therefore, we will need to create another module to generate config from an analysis request.
Regular Retrospective AA graph
We propose the following changes to the regular (non-Hypercube) graph. The parts that need to be changed are circled. In summary, we will replace the modules in the purple circle, and delete all the modules from the red circle.
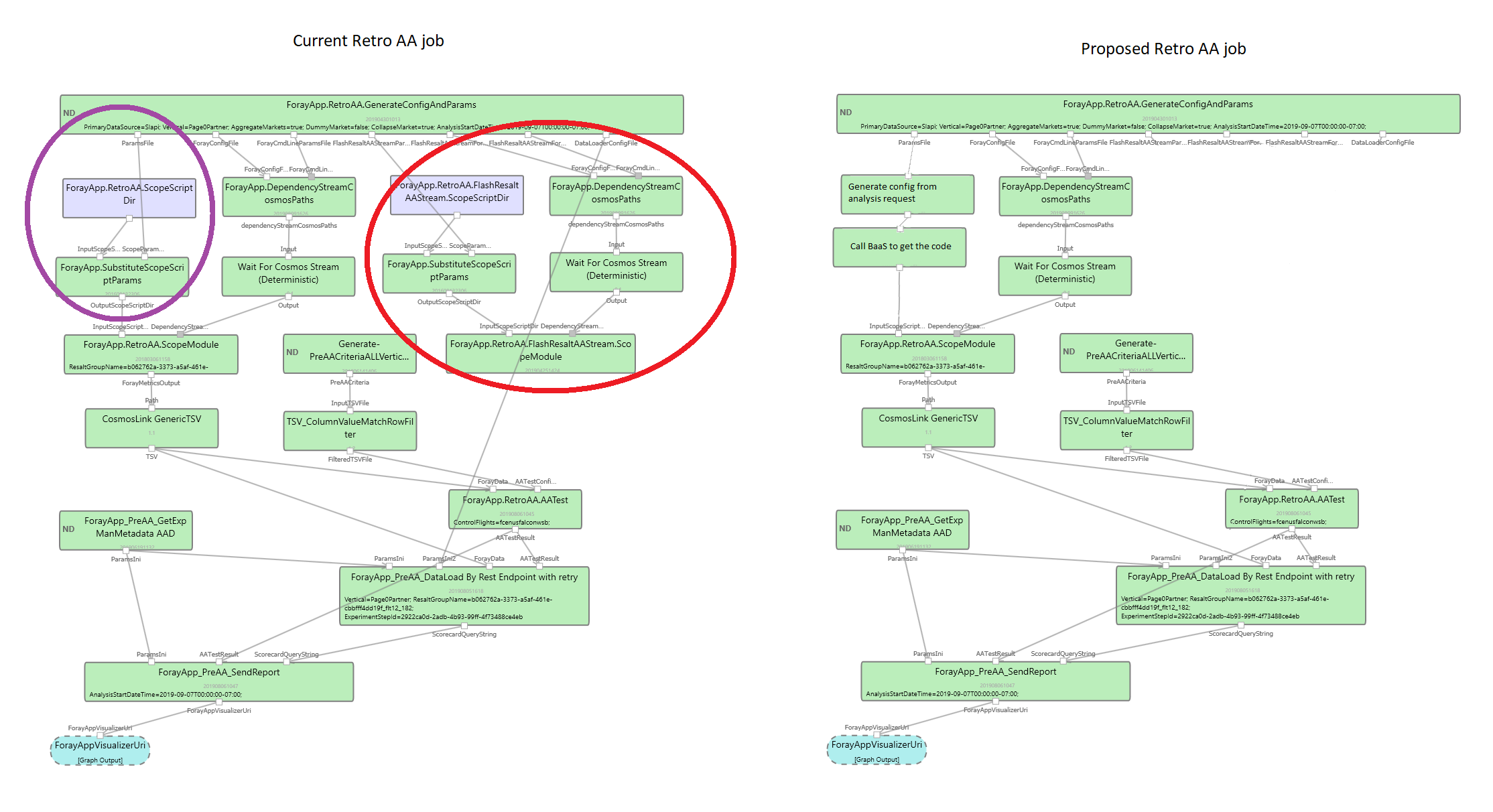
Right now there is a saved script with wildcards that are being replaced in the module
using the information from the config (the ForayApp.SubstituteScopeScriptParams module).
The right side of the graph computes the "FlashResaltStream", which is basically the output
of the experiment unit level aggreagtion. We would replace both this right side of the graph
and the ForayApp.SubstituteScopeScriptParams module with two new modules.
The first module would generate an extended config file from the analysis request
(we say "extended" because it contains all the required information for the Retro AA job which
is not normally present in Blitz configs). The generated config would be passed to the second module,
which would make a call to Blitz as a Service (BaaS) sending the extended config file
and getting the generated Scope code back. The extended config will contain all the necessary information
for the Retro AA job and would use the Retro AA Blitz extension described above
to modify the MetricsPlan.
Hypercube Retrospective AA graph
Some partners (e.g. Bing) use another version of Retro AA that uses Hypercube to create scorecards.
However, the part of the graph that creates FlashResaltAAStream is still using xForay.
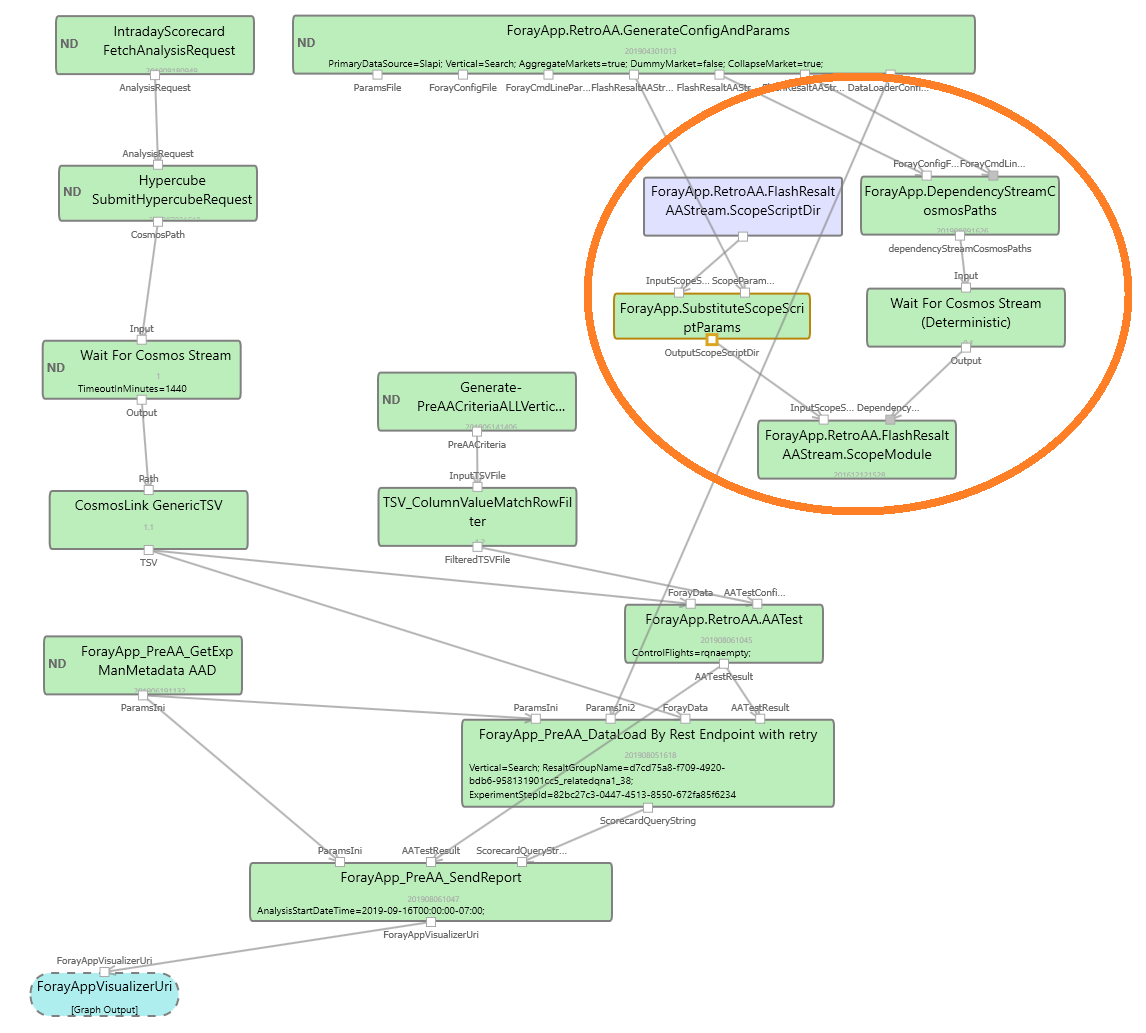
We propose replacing the right side of the graph (circled by orange circle)
with the "generate config from analysis request" and "Call to Blitz" modules as for the usual Retro AA graph (described above),
followed by the module running the generated Scope code. This would mean that we will be doing some extra computation
since instead of stopping at the experiment unit level and outputting the FlashResaltAAStream,
we fully compute the scorecard.
Note: This is not ideal, but the aggregation from experiment unit level
to flight is generally fast, but it will save the overhead of creating a separate Blitz extension
for the FlashResaltAAStream generation. In the future, we plan to decouple this from Retro AA.
Similar to the regular Retro AA,
Remark on ForayApp.DependencyStreamCosmosPaths module
Besides the modules mentioned above, each of the Retro AA graphs has only one module left
that still depends on Foray, namely ForayApp.DependencyStreamCosmosPaths. This module uses
Foray to retrieve the list of stream dependencies for the job. This RFC will not discuss modifying
these modules to replace this call to Foray with a call to Mangrove. The main reason for this is that
Mangrove does not have stream dependency information and, being only a code generation framework, neither it should.
Changes to Mangrove
We propose introducing a new field to the ComputationConfig object called ExperimentUnitOutputPath.
We will create a Factory that would add a transformer inserting another output TableReference
wrapping the experiment unit table. Moreover, this would require the following changes:
- Change the
Scopeemitter to support severalOUTPUTstatements. The newExperimentUnitOutputPathparameter would only be supported forScopeandMVcompute fabrics. - The transformer should be added at the very end of the chain of transformers in the
MasterCoordinatoras one of the steps there is coalescing all the output tables. - Change the
ExperimentUnitextension method to be more general, since now it assumes the conditions of this article to be true. In particular, it assumes only oneAggregationtable at the experiment unit level. However, this is no longer true after the segmentation logic is applied, since after that the experiment unit table is in fact aUniontable aggregating manyAggregationtables.
New FilterMap aggregation level.
As described in the introduction, the virtual flight for a row of telemetry is determined by the userid and FilterMap values.
Conceptually, the user ID is by definition a user-level value, but FilterMap is technically base-level
(the same user can have telemetry with different filter values such as different markets,
devices/platforms, build versions etc.) In practice, the number of unique FilterMap values per user is very small,
suggesting that computation can be optimized by not deriving the flight on base-level
but instead at a higher aggregation level. The easiest optimization is to insert a FilterMap
aggregation level directly above base and compute FLIGHT at that level. Since all operations in Mangrove are recursive,
this does not cause any problems with correctness. This is contrary to the common assumption that FLIGHT is a constant at base-level,
though, and we need to ensure that all parts of the compute stack handle this correctly.
Treating FLIGHT as a segment solves this, since segments can be defined at any aggregation level.
In the current system, SeedFinder implements this optimization, but for Retro-AA FLIGHT is computed at base-level. Due to the enforced recursive properties of all metric computations in Mangrove, we can extend this optimization to both scenarios and metrics at all levels (currently SeedFinder only supports user-level metrics according to user feedback).
Changes to Metrics Vectorization
- The MetricsVectorization (MV) code currently performs all aggregations in a single processor. To enable intermediate-level output capabilities (such as the user-level output from the Retro-AA job), we will need to be able to split this into multiple processor calls.
- Currently FLIGHT is handled separately from other segments. To align with Mangrove, we will treat is as a standard segment.
Alternative approaches
Alternative 1: directly provide all the necessary information to Mangrove
In this case, we need to change RandomizationConfiguration object from Coordinator.Configuration.Contract
to add the missing the output path and the list of metrics for the seedfinder. Moreover, this would require adding
an AnalysisType parameter to the config to determine which transformers need to be added
based on the type of analysis (e.g. regular A/B, business, retro AA, seedfinder). Additional
transformers need to be implemented to do the modifications that were suggested to be done inside
Blitz extensions.
Alternative 2: creating a Blitz config template in AEther
Instead of making the changes to the Config Gen, we can simply create a template in AEther with wildcards for all the Retro AA specific parameters, and simply use the current AEther inputs to fill the parameters in. This would still require the same changes to Mangrove but would save the changes to the config gen service.
We believe this solution is not optimal because it would make it hard to make updates if the requirements change: instead of a simple Mangrove + Config Gen update it would also require searching for all ther AEther modules using the templates and updating each of them.